The Adversarial Pivotal Tuning (APT) framework
![alt]()
In the first step, we optimize a style code wp using standard latent optimization Lo, while keeping the generator G frozen.
The loss is computed between the ground-truth image xgtr and the generated image xgen.
In the second step, we freeze wp and finetune G (shown in red) using the three objectives; a
reconstruction objective Lrec, the projected GAN objective using the discriminator D, LP G, and our fooling objective LCE using the
classifier C. A ∗ is used to indicate a frozen component
Manipulations using different classifiers
![alt]()
Top row shows input images. The middle row shows APT manipulations for a ResNet-50 classifier,
and the bottom row shows APT manipulations from a FAN-VIT classifier. The leftmost image of a dog and the subsequent images including
the image of a butterfly and column 7 (Fluffy dog) show similar manipulations for both classifiers, column 5-6 shows texture and spatial
manipulations, the last column showcase a fooling image without a clear APT manipulati
Transferability of APT generated samples
![alt]()
For the ImageNet-1k validation set, we consider samples generated to fool a PRIME-Resnet50 (PRIME) and a FAN-VIT (FAN) pretrained classifier. We then test the accuracy (Acc) and mean softmax probability
of the labelled class (Conf) on those samples. The left column indicates the classifier on which we tested the accuracy of real or generatedsamples. ∗ indicates the accuracy and confidence of samples generated and tested using the same classifier.
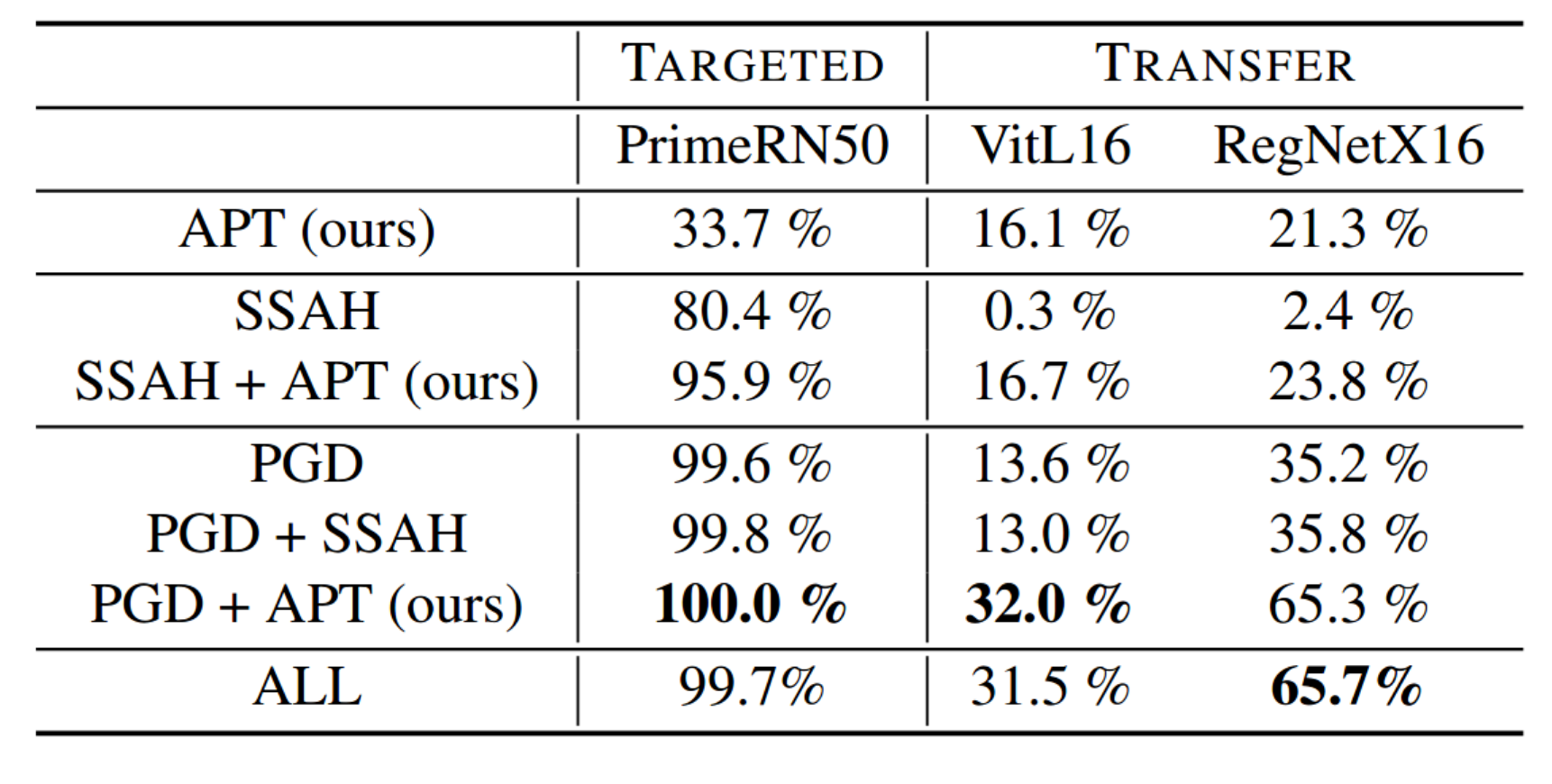
Attack Success Rate (ASR) for APT, SSAH and PGD
![alt]()
We investigate the attack success rate for our method APT against more traditional but imperceptible attacks such as PGD and SSAH.
Additionally we also test how well these generated images can fool other classifiers that was not subject to an attack.
An example of these attacks are illustrated here
![alt]()
Average accuracy and confidence on APT samples using PRIME-ResNet50 before and after fine-tuning.
![alt]()
We investigate the effect of finetuning a PRIME-ResNet50 model on our generated fooling images usng APT, PGD and SSAG.
We find that the accuracy to correcly predict the original class increases after finetuning for each indidual attack
but also when combining all attacks.
Acknowledgement
This research was supported by the Pioneer Centre for AI, DNRF grant number P1.