We present PAPYER ![]() , a dataset collected for narrative discovery in social media discussions using a human in the loop pipeline and a combination of human and machine kernels.
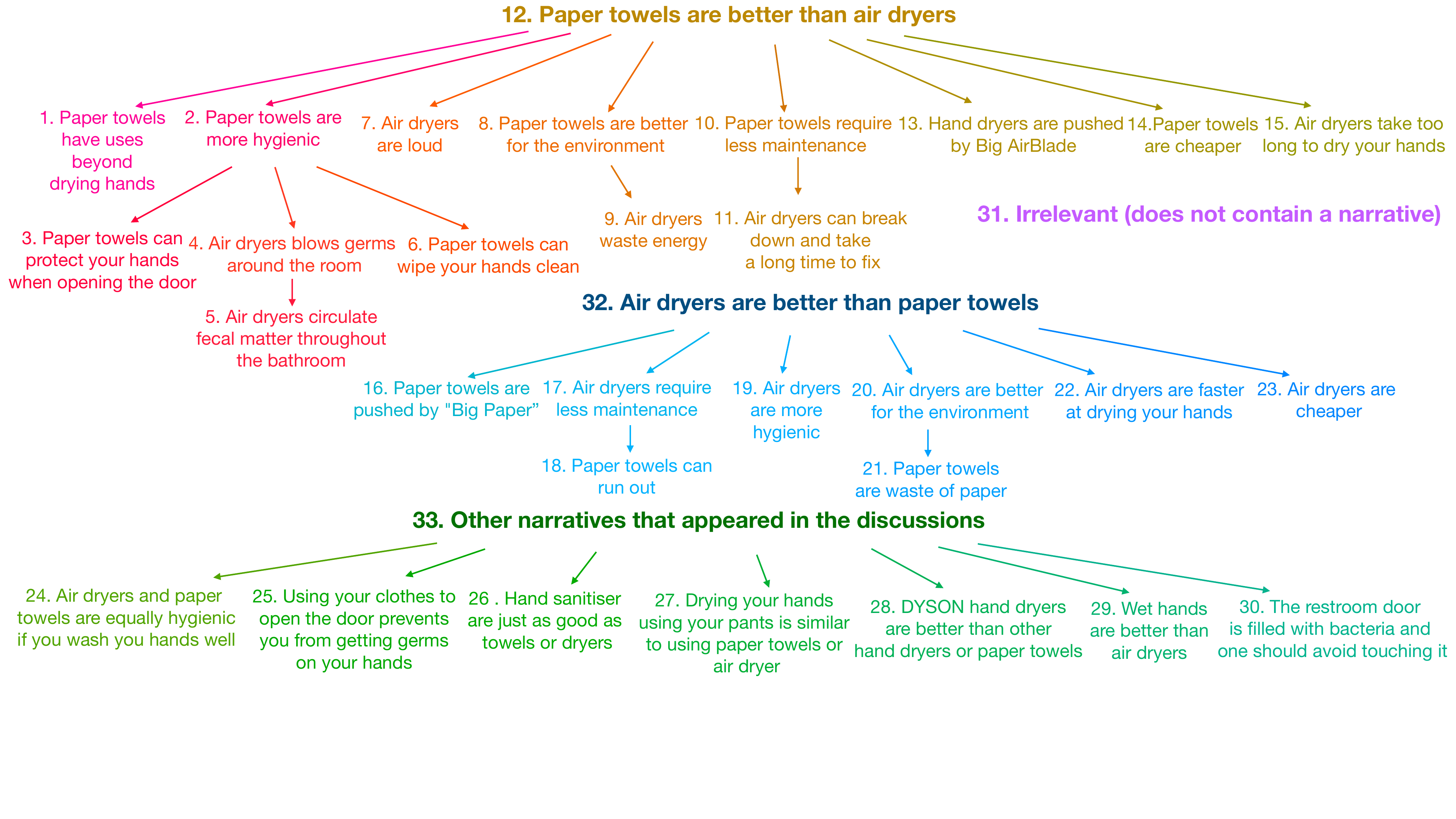
Our method relies on SNaCK and compares favorably to prior topic modelling and transformer-based methods and discovers a low dimensional space of narratives revolving around hygiene in public restrooms using less than 30k triplets.
Our long-term vision is analogous to Visipedia: we wish to capture and share human narratives in online discussions across a wide array of topics.
The present work represents our first foray in this direction, with a deep dive into a single topic.
, a dataset collected for narrative discovery in social media discussions using a human in the loop pipeline and a combination of human and machine kernels.
Our method relies on SNaCK and compares favorably to prior topic modelling and transformer-based methods and discovers a low dimensional space of narratives revolving around hygiene in public restrooms using less than 30k triplets.
Our long-term vision is analogous to Visipedia: we wish to capture and share human narratives in online discussions across a wide array of topics.
The present work represents our first foray in this direction, with a deep dive into a single topic.